
L’applicazione web “Revisore Accademico Plus” è strutturata per l’editing testuale tramite Intelligenza Artificiale secondo stretti protocolli di integrità. L’obiettivo tecnico del software è limitare il ruolo dei modelli alla sola assistenza formale (grammatica, fluidità, coerenza parziale), impedendo l’alterazione di argomentazioni o l’aggiunta di dati non preventivamente forniti.
Flusso Operativo (Infografica)
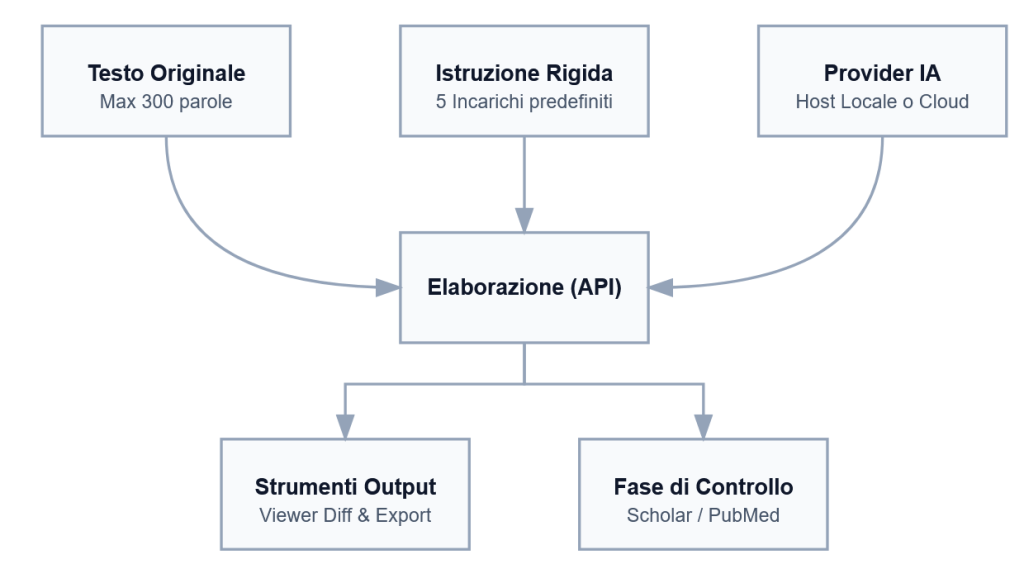
Funzionalità Integrate
- Limiti Sezione (“Small Sections”): È presente un controllo visivo del contatore parole per far sì che la porzione di testo da processare risulti esigua, abbattendo alterazioni secondarie impreviste del modello linguistico.
- Gestione Prompt: La selezione delle istruzioni avviene tramite l’attivazione di schede in UI piuttosto che da digitazione manuale dell’utente, stabilizzando e standardizzando la comunicazione verso l’IA.
- Integrazione Provider: Interfaccia a tendina preimpostata per lo switch tra server interni (LM Studio, Ollama) ed esterni con API Keys (OpenAI, Gemini, Anthropic). Una query di background può prelevare la lista dei modelli correntemente installati in locale.
- Comparazione Diff e Archiviazione: Al termine della generazione, sono accessibili tre output metodologici: evidenziatore del differenziale linguistico calcolato localmente (Diff), esportazione di elaborati Word per office automation (.docx), ed esportazione di elaborati Markdown (.md).
- Toolbar Transazionale: Una raccolta di reindirizzamenti diretti ai database di letteratura scientifica e un gestore nativo della clausola di esonero della responsabilità generativa per la conformità di trasparenza editoriale.
Installazione e Configurazione Componenti Locali
1. Parametrizzazione di LM Studio
LM Studio gestisce l’esecuzione locale e la ramificazione dei modelli Open Source dotandoli di un access point compatibile con le API OpenAI.
- Scaricare il pacchetto ed eseguire l’installazione dal sito lmstudio.ai.
- Avviare il software e individuare un modello (es. Llama-3-8B-Instruct o gemma-2b-it) dalla finestra “Search” scaricando la quantizzazione adatta al proprio hardware.
- Accedere alla visualizzazione “Local Server” (la rispettiva icona sul pannello laterale).
- Attivare il processo server interagendo con il tasto Start Server.
- Controllare che i parametri avanzati di rete (“CORS”) riportino l’autorizzazione d’accesso generale ad altri script (se l’opzione esiste, abilitarla).
- Nel file di lavoro RevisoreAccademicoPlus.html, impostare il Provider IA su LM Studio (Locale). L’interfaccia configurerà automaticamente l’endpoint all’URL http://localhost:1234/v1/chat/completions.
- Usare il tasto Ricerca Modelli 🔄 per autocompletare il pannello del modello con gli ID disponibili in RAM.
2. Parametrizzazione di Ollama
Ollama funge da runtime da riga di comando per operare istanze IA efficienti di dimensione quantizzata come daemon operativi.
- Ripercorrere le direttive d’installazione ufficiali (ollama.com/download) per il conseguimento dell’eseguibile sul proprio OS.
- Per eseguire il download asincrono dei modelli, invocare l’applicazione all’interno di un prompt/terminale con i rispettivi moduli. Es: ollama run llama3.
- Gestione del Cross-Origin Security Block (CORS): Affinché il gestore HTTP dell’applicazione RevisoreAccademicoPlus.html locale possa dialogare con l’istanza generativa senza ricevere un errore “Access-Control-Allow-Origin”, è obbligatorio esplicitare le autorizzazioni all’avvio:
- Su Sistema Windows (Prompt Comando CMD): set OLLAMA_ORIGINS=”*” seguito da ollama serve (eseguire l’ultimo stando in una medesima finestra di amministrazione).
- Su Sistema Windows (PowerShell): $env:OLLAMA_ORIGINS=”*”
- Su Sistemi UNIX/Mac: OLLAMA_ORIGINS=”*” ollama serve.
- Nella Web UI selezionare Ollama (Locale) e confermare il riempimento automatico in http://localhost:11434/api/generate. Usare la funzionalità Ricerca Modelli 🔄 posta sulla Web UI.
scaricare App e Manuale
